|
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention |
Kelvin Xu*,
Jimmy Lei Ba†,
Ryan Kiros†,
Kyunghyun Cho*,
Aaron Courville*,
Ruslan Salakhutdinov†,
Richard Zemel†,
Yoshua Bengio*
University of Toronto†/University of Montreal*
Overview
-
Image caption generation is the problem of generating a descriptive
sentence of an image. The fact that humans (e.g you) can do this with
remarkable ease makes this a very interesting/challenging problem for
AI, combining aspects of computer vision (in particular scene
understanding) and natural language processing.
In this work, we introduced an "attention" based framework into the problem of image caption generation. Much in the same way human vision fixates when you perceive the visual world, the model learns to "attend" to selective regions while generating a description. Furthermore, in this work we explore and compare two variants of this model: a deterministic version trainable using standard backpropagation techniques and a stochastic variant trainable by maximizing a variational lower bound.
How does it work?
-
The model brings together convolutional neural networks, recurrent neural networks
and work in modeling attention mechanisms.
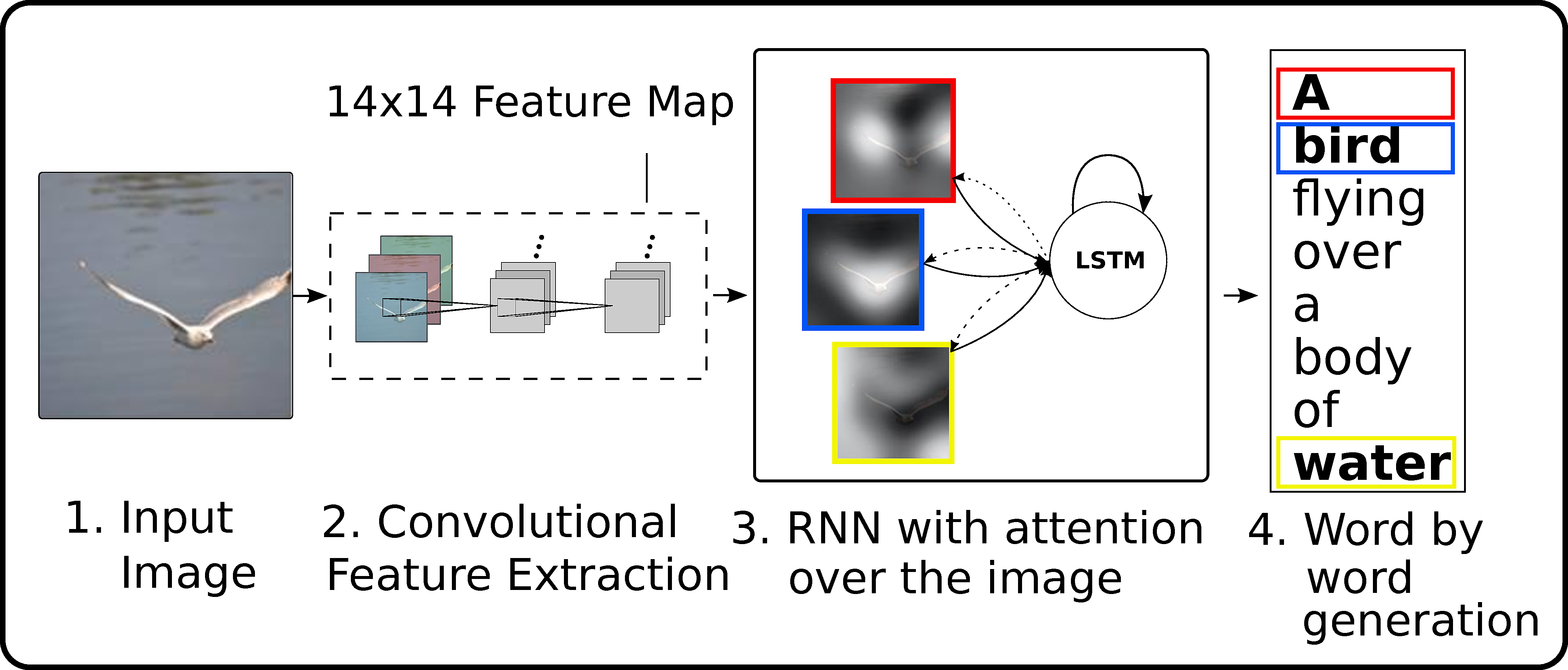
Above: From a high level, the model uses a convolutional neural network as a feature extractor, then uses a recurrent neural network with attention to generate the sentence.
-
If you are not familiar with these things, you can think of the convolutional network as
an function encoding the image ('encoding' = f(image)), the attention mechanism as grabbing a
portion of the image ('context' = g(encoding)), and the recurrent network a word
generator that receives a context at every point in time ('word' = l(context)).
For a roadmap and a collection of material explaining some of the networks used in this work, see the following on convolutional and recurrent neural networks.
The model in action












Want all details? Interested in what else we've been up to?
Please check out the following technical report and visit the pages of the authors:-
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention (2015)
K. Xu , J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhutdinov, R. Zemel, Y. Bengio
Or contact us
Code